
「Orphaned configuraion. ...」というアラートメッセージで検索するとCubeMXの次期バージョンで対応とかなんとか出てきますがよくわかりません。
TrueSTUDIOと同じく無償のSTM32の開発環境のSW4STM32も少し使ってみました。
SW4STM32について
「System Workbench for STM32」の略称で、「Atollic TrueSTUDIO」と同じくEclipseベースの統合開発環境です。
STM32CubeMXでプログラムの雛形を作るとTrueSTUDIOでもSW4STM32でも簡単なプログラムを書く場合はそれほど違いがありません。
参考にした記事
「電子工作専科」さんの「System workbench for STM32」
Nucloe-F446REで単精度浮動小数点数演算の速度比較
今まで、mbedを使ってきましたが、STM32のネイティブ環境であるTrueSTUDIOとSW4STM32で単精度浮動小数点数演算の速度を比較しました。
- STM32CubeMX Version: 5.1.0
- TrueSTUDIO for STM32 Version: 9.3.0
- System Workbench for STM32 - C/C++ Embedded Development Tools for MCU Version: 2.7.2.201812190825
- mbed-cli Version: 1.9.1
#include "mbed.h" #include <stdio.h> #include <math.h> #define PI_F (3.14159265f) #define LOOP_N (1000) DigitalOut CheckPin1(D2); volatile float buffer[LOOP_N]; int main() { while (true) { CheckPin1 = 1; float fv = 0.0f; for (int i = 0; i < LOOP_N; i++) { fv += 0.001f; //buffer[i] = fv + PI_F; // Add //buffer[i] = fv - PI_F; // Sub //buffer[i] = fv * PI_F; // Mul //buffer[i] = fv / PI_F; // Div buffer[i] = sinf(fv); //buffer[i] = cosf(fv); //buffer[i] = tanf(fv); //buffer[i] = expf(fv); //buffer[i] = logf(fv); //buffer[i] = powf(2.0f, fv); } CheckPin1 = 0; } }
float型の演算結果をbufferに代入するのを1000回繰り返し、その前後でGPIOの出力をH/Lさせています。それぞれの演算はコメントアウトしたり外したりして再ビルドするという地道な方法で測定しました。


測定データ(us)
| / | TrueSTUDIO | SW4STM32 | mbed-cli |
|---|---|---|---|
| no-op | 22.15 | 22.15 | 0.06108 |
| add | 77 | 82.6 | 44.5 |
| sub | 82 | 82.4 | 44.5 |
| mul | 82.6 | 82.6 | 44.5 |
| div | 138 | 137 | 111 |
| sinf() | 547 | 515 | 536 |
| cosf() | 607 | 581 | 588 |
| tanf() | 1050 | 1002 | 926 |
| expf() | 990 | 1122 | 926 |
| logf() | 934 | 982 | 906 |
| powf() | 4090 | 2995 | 2585 |
「no-op」というのはbufferへの代入を全てコメントアウトして、「fv += 0.001f;」という演算のみでループさせた場合です。mbed-cli(グレーの縦棒)では処理が速すぎてグラフに表示されていません。
mbed

TrueSTUDIO

SW4STM32

mbedよりSTM32のネイティブ環境の方が速くなるんではないかと思っていたのですが、mbedの方が高速という結果です。
mbedの場合は1000回演算を16MHzで処理してるので、180MHz駆動ではあからさまにおかしいと思いますが、最適化の具合?
TrueSTUDIO/SW4STM32のコンパイル/リンクオプション
TrueSTUDIO
[C Compiler]
Command: arm-atollic-eabi-gcc -c
All options:
-mthumb -mcpu=cortex-m4 -mfloat-abi=hard -mfpu=fpv4-sp-d16 -std=gnu11 -D__weak=__attribute__((weak)) -D__packed=__attribute__((__packed__)) -DUSE_HAL_DRIVER -DSTM32F446xx -I../Inc -I../Drivers/STM32F4xx_HAL_Driver/Inc -I../Drivers/STM32F4xx_HAL_Driver/Inc/Legacy -I../Drivers/CMSIS/Device/ST/STM32F4xx/Include -I../Drivers/CMSIS/Include -Og -ffunction-sections -fdata-sections -g -fstack-usage -Wall -specs=nano.specs
[C Linker]
-mthumb -mcpu=cortex-m4 -mfloat-abi=hard -mfpu=fpv4-sp-d16 -std=gnu11 -D__weak=__attribute__((weak)) -D__packed=__attribute__((__packed__)) -DUSE_HAL_DRIVER -DSTM32F446xx -I../Inc -I../Drivers/STM32F4xx_HAL_Driver/Inc -I../Drivers/STM32F4xx_HAL_Driver/Inc/Legacy -I../Drivers/CMSIS/Device/ST/STM32F4xx/Include -I../Drivers/CMSIS/Include -Og -ffunction-sections -fdata-sections -g -fstack-usage -Wall -specs=nano.specs
SW4STM32
[MCU GCC Compiler]
Command: gcc
All options:
-mcpu=cortex-m4 -mthumb -mfloat-abi=hard -mfpu=fpv4-sp-d16 -D__weak=__attribute__((weak)) -D__packed=__attribute__((__packed__)) -DUSE_HAL_DRIVER -DSTM32F446xx -I../Inc -I../Drivers/STM32F4xx_HAL_Driver/Inc -I../Drivers/STM32F4xx_HAL_Driver/Inc/Legacy -I../Drivers/CMSIS/Device/ST/STM32F4xx/Include -I../Drivers/CMSIS/Include -Og -g3 -Wall -fmessage-length=0 -ffunction-sections -c -fmessage-length=0
[MCU GCC Linker]
Command: gcc
All options:
-mcpu=cortex-m4 -mthumb -mfloat-abi=hard -mfpu=fpv4-sp-d16 -specs=nosys.specs -specs=nano.specs -u _printf_float -T"../STM32F446RETx_FLASH.ld" -Wl,-Map=output.map -Wl,--gc-sections -lm
TrueSTUDIOで「Add」した場合のウオッチ

誤差は出ていますが、πの値に0.001ずつ加算されていると思います。
STM32CubeMXでNucleo-F446REは180MHz駆動する設定にしています。
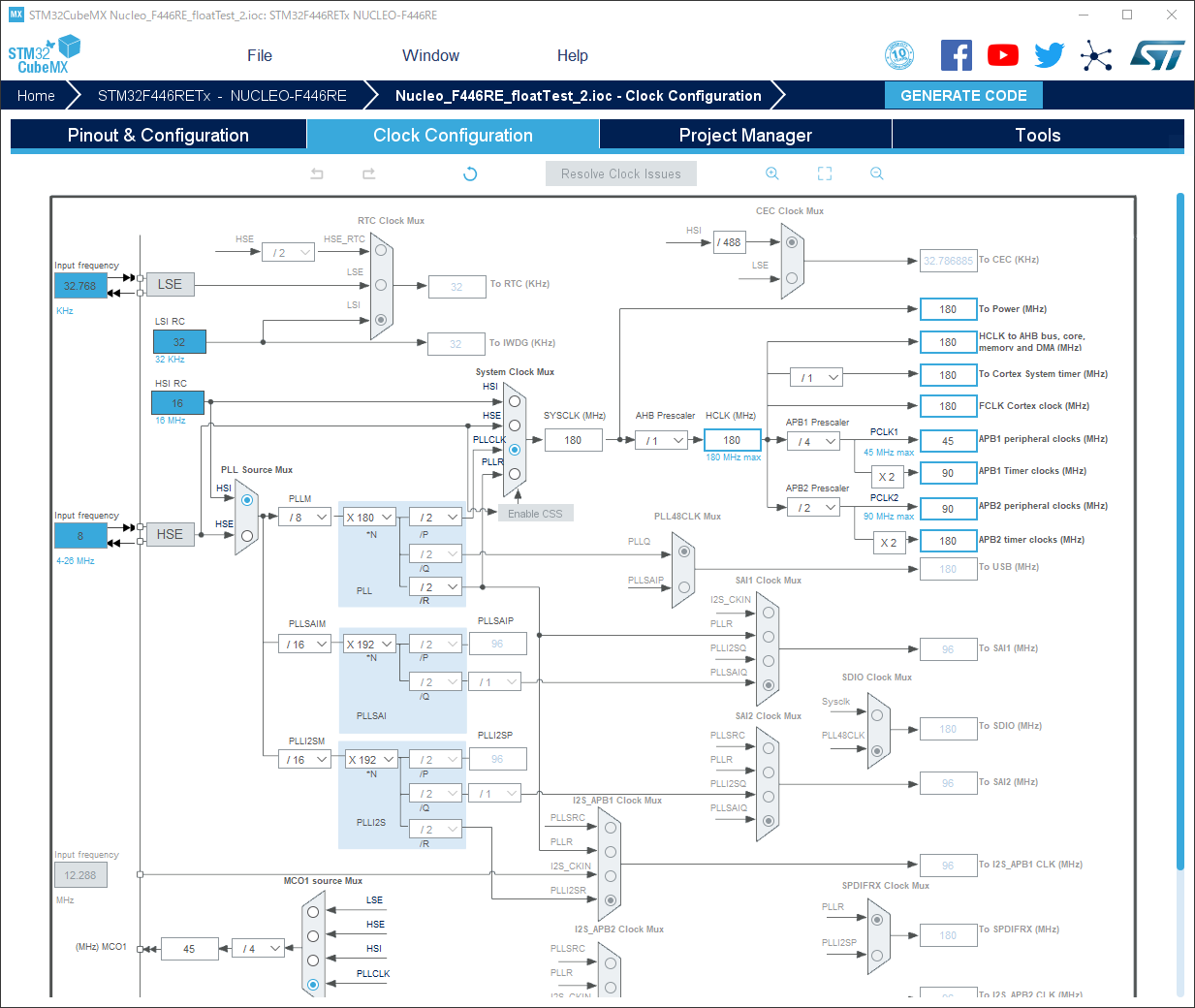
メモ:
TrueSTUDIOでは、sprintf()でfloatを使うときは、[General]-[Runtime Library]で[Newlib standard]を選択する。

IDEでのFPUの設定


CMSIS DSPにFAST MATH FUNCTIONがあるが、sine/cosine/sqrtのみ。DSPはベクトル演算で本領を発揮するので、関係はなさそう。
0 件のコメント:
コメントを投稿