Nucleo用にmbedで書いたプログラムとほぼおなじものをRaspberry Pi3用にC++で書いて比較してみた。
Nucleo用プログラム (mbed)
https://os.mbed.com/users/ryood/code/FloatingPointTest/ Revison:1
Raspberry Pi 3用プログラム <floating_point_test.cc>
#include <stdio.h>
#include <math.h>
#include <time.h>
#include <stdint.h>
#define LOOP_N (10000)
float buffer[LOOP_N];
clock_t start;
void floatTest()
{
// divf
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = (float)i / LOOP_N;
}
int elapse = clock() - start;
printf("divf\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// sinf
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = sinf((float)i / LOOP_N);
}
elapse = clock() - start;
printf("sinf\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// cosf
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = cosf((float)i / LOOP_N);
}
elapse = clock() - start;
printf("cosf\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// expf
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = expf((float)i / LOOP_N);
}
elapse = clock() - start;
printf("expf\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// logf
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = logf((float)i / LOOP_N);
}
elapse = clock() - start;
printf("logf\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// sqrtf
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = sqrtf((float)i / LOOP_N);
}
elapse = clock() - start;
printf("sqrtf\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
}
void doubleTest()
{
// div
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = (double)i / LOOP_N;
}
int elapse = clock() - start;
printf("div\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// sin
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = sin((double)i / LOOP_N);
}
elapse = clock() - start;
printf("sin\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// cos
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = cos((double)i / LOOP_N);
}
elapse = clock() - start;
printf("cos\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// exp
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = exp((double)i / LOOP_N);
}
elapse = clock() - start;
printf("exp\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// log
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = log((double)i / LOOP_N);
}
elapse = clock() - start;
printf("log\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
// sqrt
start = clock();
for (int i = 0; i < LOOP_N; i++) {
buffer[i] = sqrt((double)i / LOOP_N);
}
elapse = clock() - start;
printf("sqrt\t%d\t%f\r\n", elapse, (float)elapse / LOOP_N);
}
int main()
{
printf("\nFloating Point Test\n");
printf("CLOCKS_PER_SEC: %ld\n", CLOCKS_PER_SEC);
// 単精度浮動小数点演算
printf("\nFloating Point Test\n");
printf("float\n");
printf("op\ttotal\t1-op\n");
printf("-------------------------------\n");
floatTest();
// 倍精度浮動小数点演算
printf("double\n");
printf("op\ttotal\t1-op\n");
printf("-------------------------------\n");
doubleTest();
}
pi@raspberrypi:~ $ gcc -o floating_point_test -lm floating_point_test.cc
pi@raspberrypi:~ $ cat /etc/debian_version
8.0
Raspberry PiのプログラムはLinux上で実行しているのでNucleoの方が有利ですが、Raspberry PiをOSなし(ベアメタルと言うそうです)で動かすのはかなり難しいので、実用的な性能比較ということになると思います。
実行結果
Floating Point Test
CLOCKS_PER_SEC: 1000000
Floating Point Test
float
op total 1-op
-------------------------------
divf 629 0.062900
sinf 2124 0.212400
cosf 2163 0.216300
expf 3632 0.363200
logf 2659 0.265900
sqrtf 3630 0.363000
double
op total 1-op
-------------------------------
div 753 0.075300
sin 4805 0.480500
cos 4829 0.482900
exp 5356 0.535600
log 4408 0.440800
sqrt 4871 0.487100
※Raspberry Pi上では実行ごとに結果が異なる。
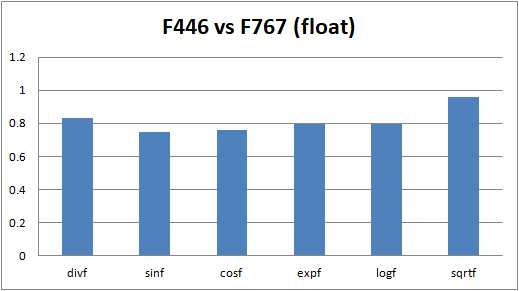
float型ではsqrtf()以外ではNucleo F767はRasPi3の約0.6倍の性能。なぜだかsqrtf()だけはNucleo F767の方が速い。
double型ではsqrt()以外はNucleo F767はRasPi3の約0.2倍~0.5倍の性能。これもsqrt()はNucleo F767の方が速い。
駆動クロックは
Nucleo F767ZI: 216MHz
Raspberry Pi 3: 1.2GHz
で約6倍差があるので、Cortex-M7のNucleo F767ZIは、まあまあ健闘していると思う。
Nucleo F767ZIの消費電流は98mAで(ボード上のJP5 IDDで測定)、Raspberry Pi 3よりかなり少ない。